TL;DR
- I read this because.. : Mentioned in CS330 lecture. In #118, it was also mentioned that using Perceiver doesn’t make any difference to IO and spring
- task : image classification, language modeling, optical flow, StarCraft II, …
- problem : I have models for each domain/task. Life would be easier if I could handle them with one NN
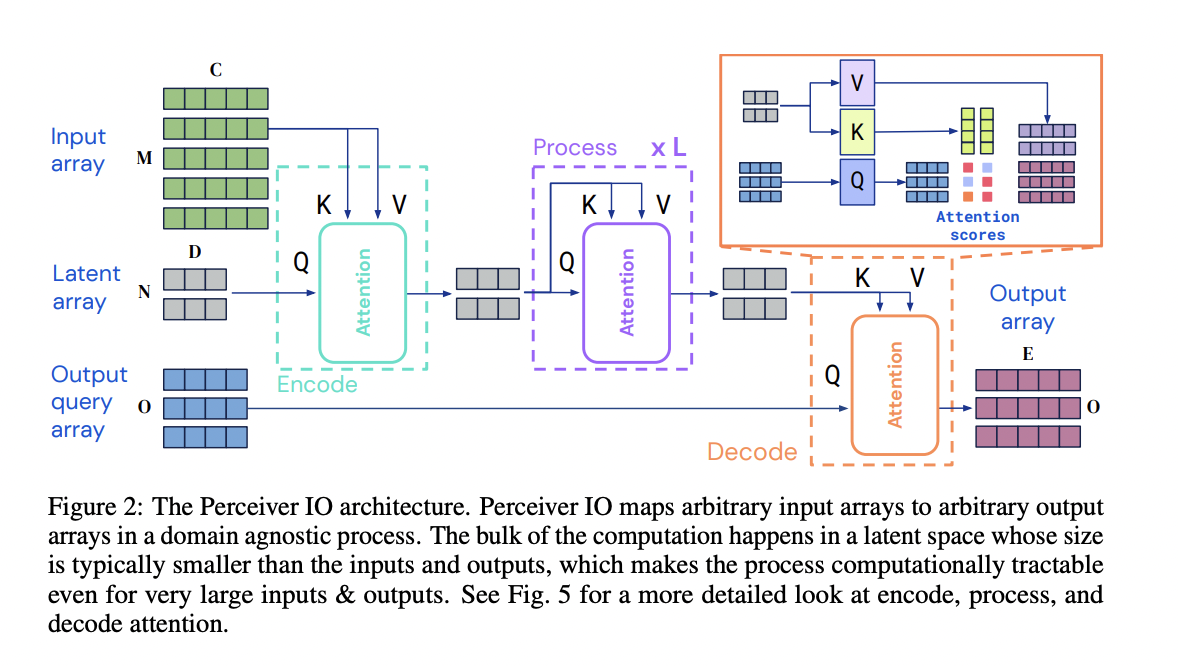
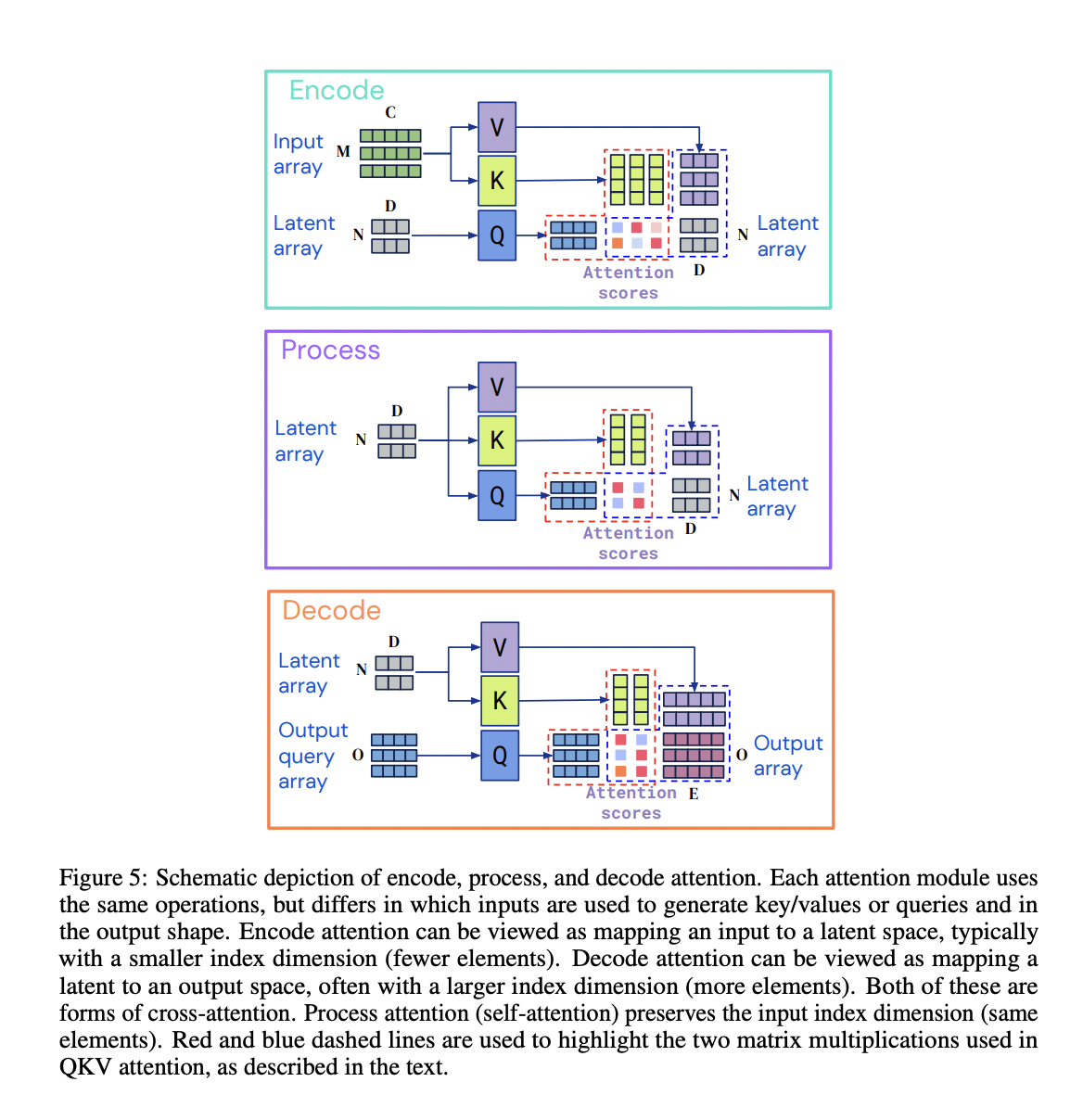
- idea : transformer encoder-decoder structure, but let’s use perceiver structure (where input modality goes to CA) + output query
- input : (encoder) N x D-dimensional latent array (decoder) positional embedding or task embedding
- output : (encoder) context vector (decoder) class(for image classification), token id(for MLM), …
- architecture : But the encoder is a perceiver (text, image, video, etc. go into the CA) / decoder is a CA between the encoder context vector and the output query.
- objective : objective function for each task
- baseline : GLUE(BERT), Image Classification(ViT-B), Optical Flow(PWCNet, RAFT), StarCraft(Transformer), AudioSet Classification(Perceiver IO)
- data : English Wikipedia + C4, ImageNet, JFT….
- result : Better performance on GLUE vs. BERT for the same FLOPS. Optical flowbars also perform well against a few metrics compared to baseline. The rest have decent performance, but not the best.
- contribution : test. for quite a few modalities. isn’t the way you put task embedding/PE embedding in the decoder a contribution point?! The rest of it seems like it’s not new
- etc. :
Details
Architecture
Output Queries
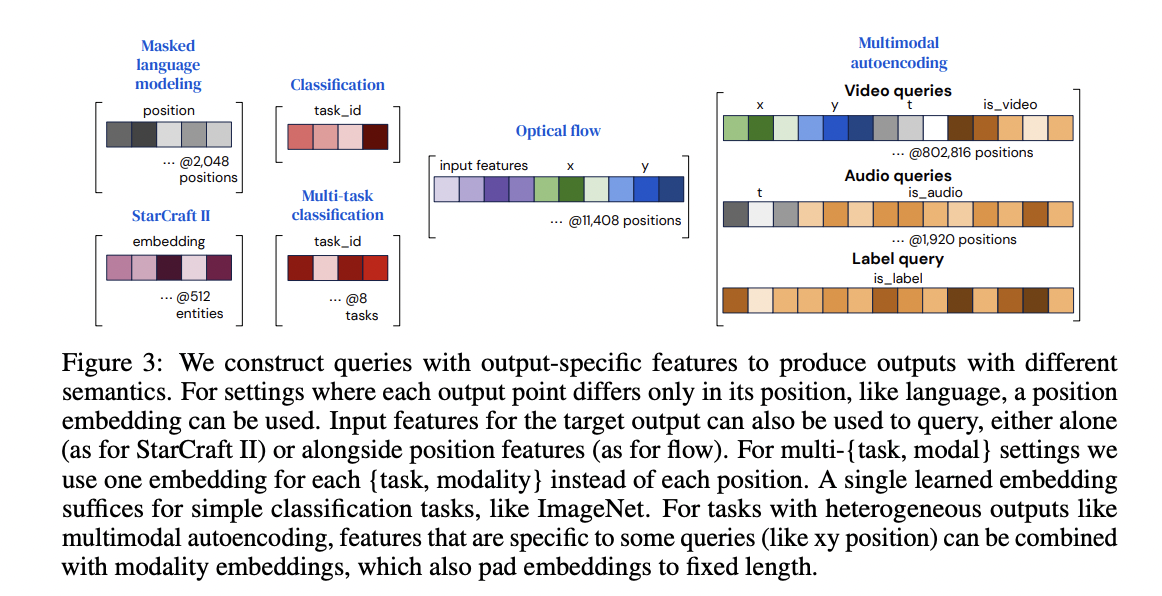
- Classification, such as image classification, can be done by simply embedding the task in the
- If multi task, multiple task embeddings
- For MLM, 2048 Positional Embeddings
Architecture Details
Result
tasks
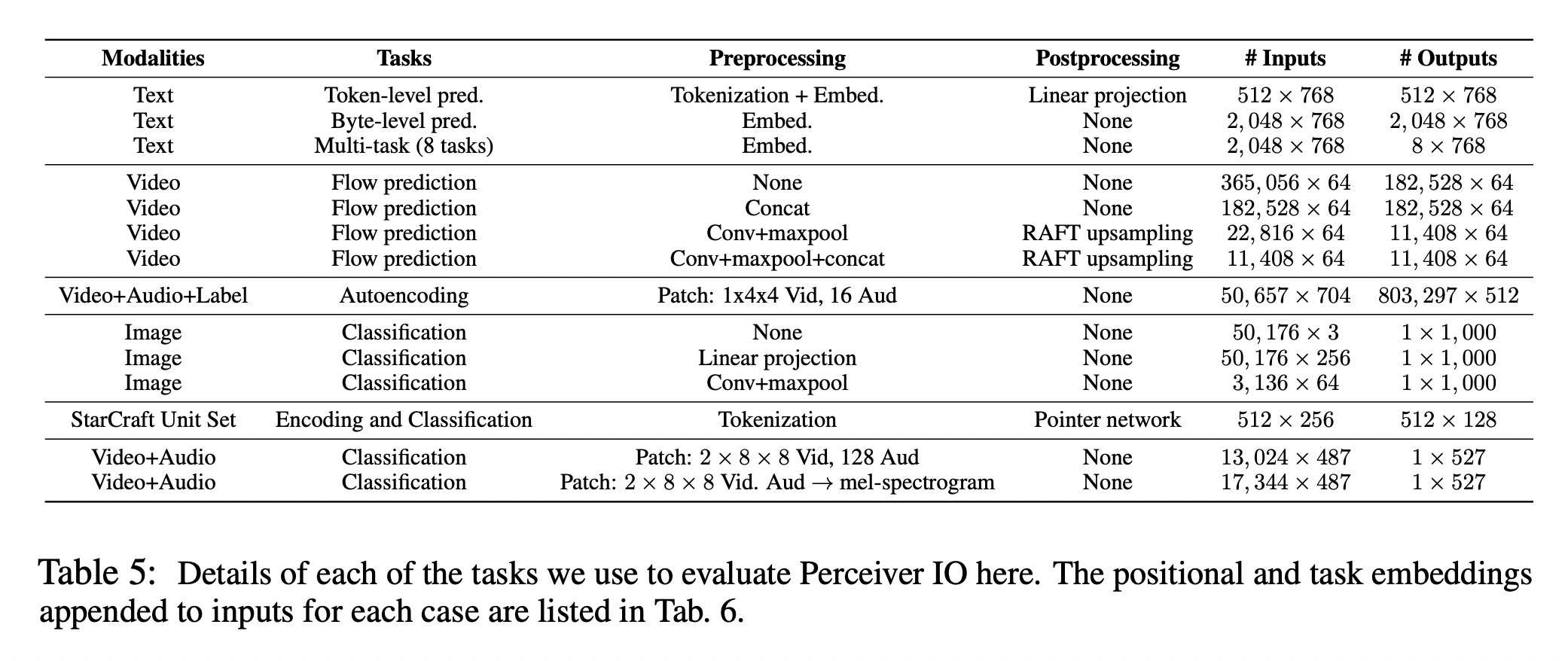
GLUE
The introduction also emphasizes using UTF-8 bytes, but I don’t know if this is a contribution (is there any prior work like BBPE?). This makes max_len longer than $$O(n**2)$$, and the structural linear increase in complexity seems to be a contribution! In this table, it has much larger parameters than BERT, but lower FLOPS. The parameter decreases the hidden dim and increases the depth by a lot. Compared to BERT, max_len was increased from 512 -> 2048 and vocab size was reduced to 256.
- image classification
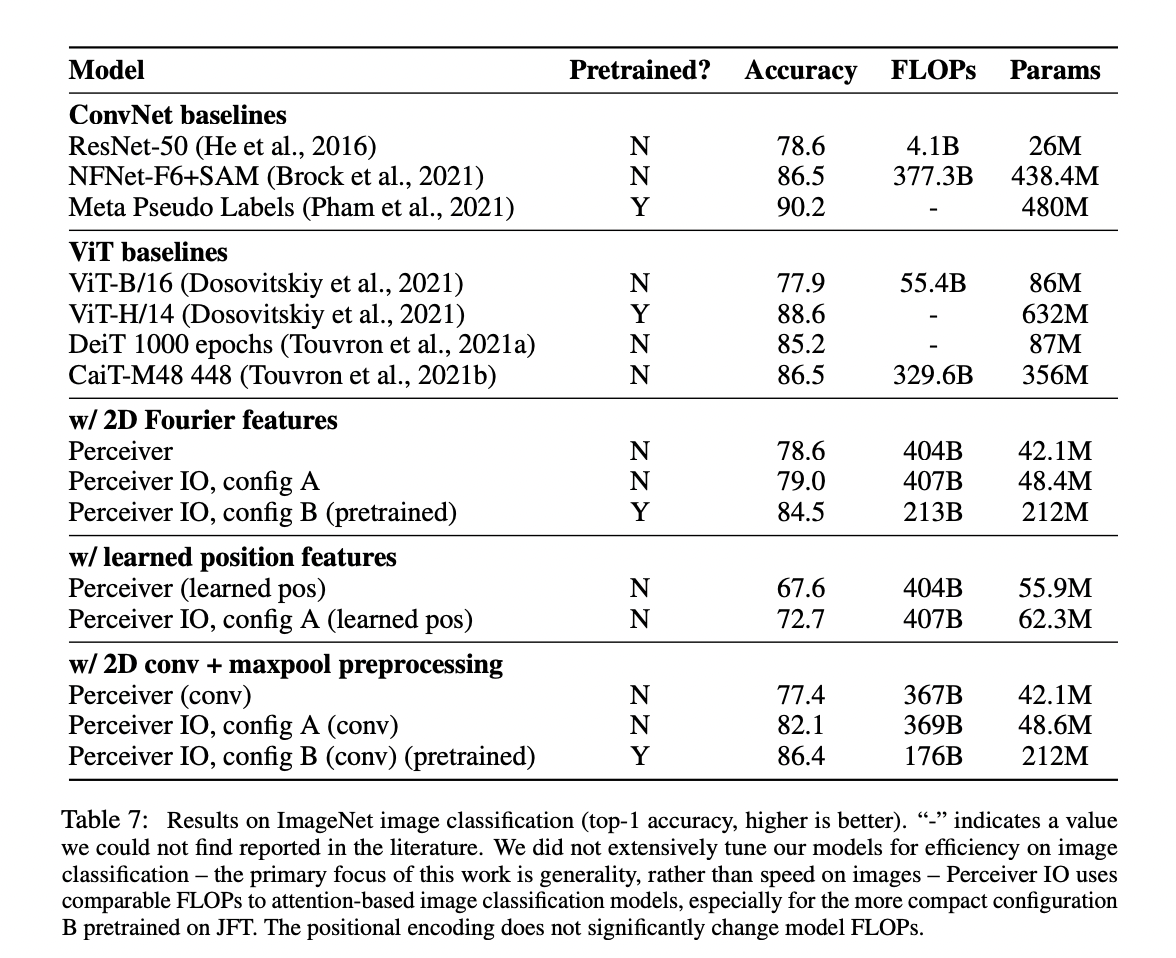
ViT-B/16ã¨ã"ã¨ã"ã’ˆã£ã¦éžå¸¸ã"ãªã’Šã¾ã-ãŸã€’ First of all, it seems worse than ViT Performance JFT pretraining scored 86.4 points, which is a bit different from ViT-H/14’s 88.6 points per viewer (although the number of parameters is 1/3). In the end, the best performance is the one with Conv. Other than that, it looks like it’s better than its predecessor Perceiver?
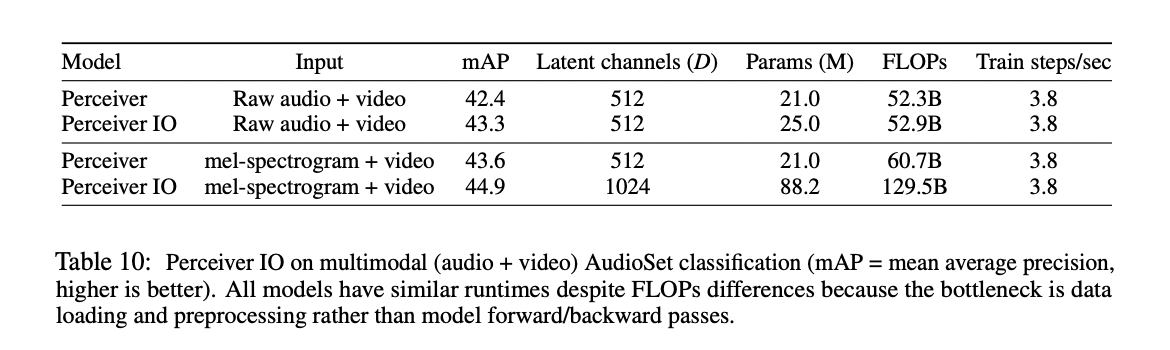
AudioSet Classification
StarCraft II