
TL;DR
- I read this because.. : NeurIPS 2023, graph
- task : multi-modal training -> image retrieval, VQA, Visual Entailment, Image Classification, GLUE
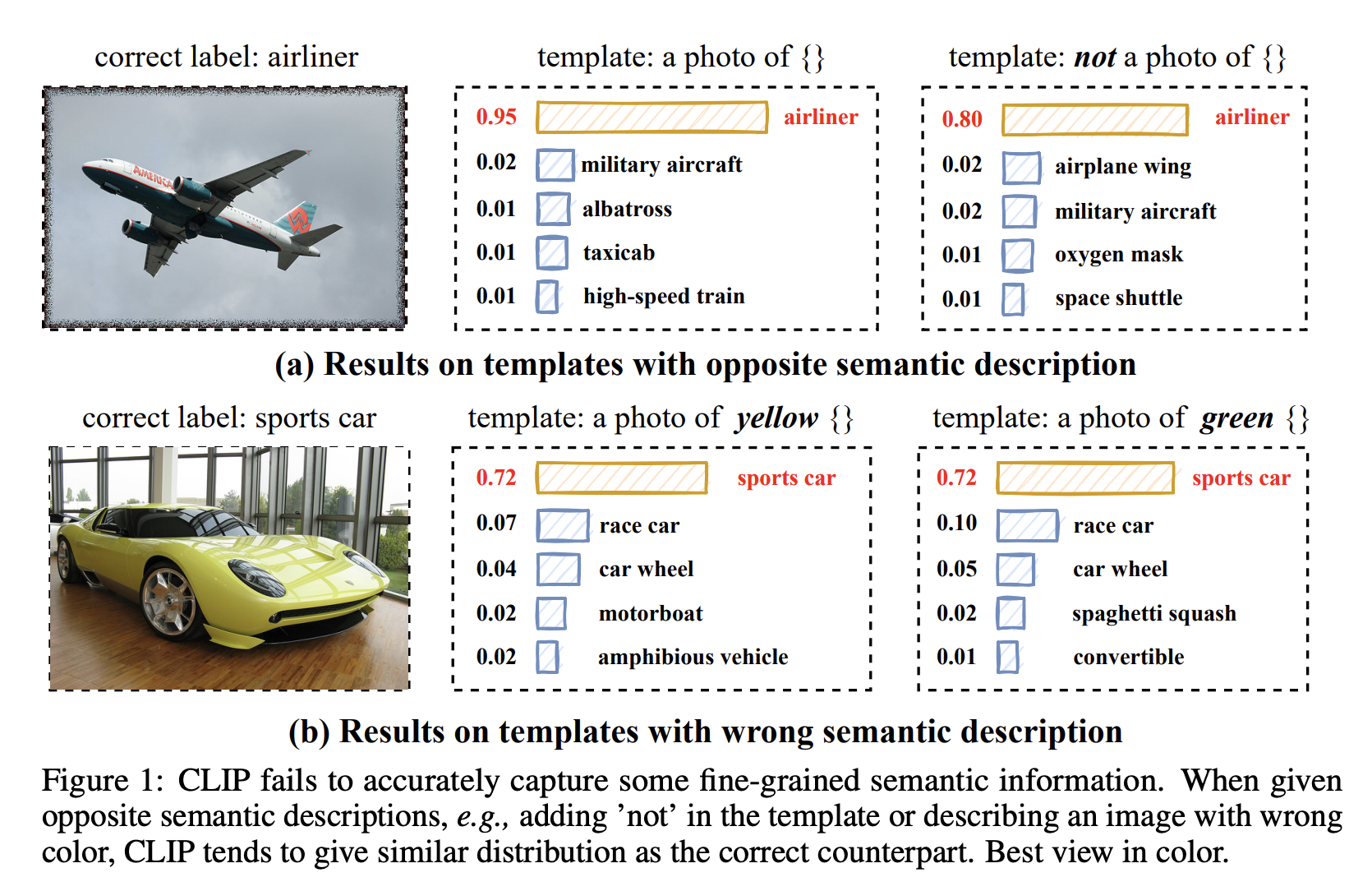
- Problem :** CLIP is too simple with only two labels, “match” and “not matched”, which does not contain any semantic information between text and image.
- idea :** CLIP + knowlege graph. takes a {head, relation, tail} triplet as input, not a text-image pair. Head or Tail can be either image or text.
- architecture : Take the CLIP architecture, but without pooling, concat + Transformer Encoder stack to pull features
- objective : Remove relation or tail (or head) from a triplet and make a prediction. 1) When removing relation, it is just a classification problem (E2R loss) 2) When removing tail, the representation of tail, head, and relation should be close to the same triplet (E2E Loss) 3) GNN is attached so that the representation of tail is similar to the representation of transformer after GNN (E2G Loss) 4) KL divergence with CLIP teacher leads to KD (KD Loss)
- baseline : CLIP, UNITER, OSCAR, ViLT, … and more
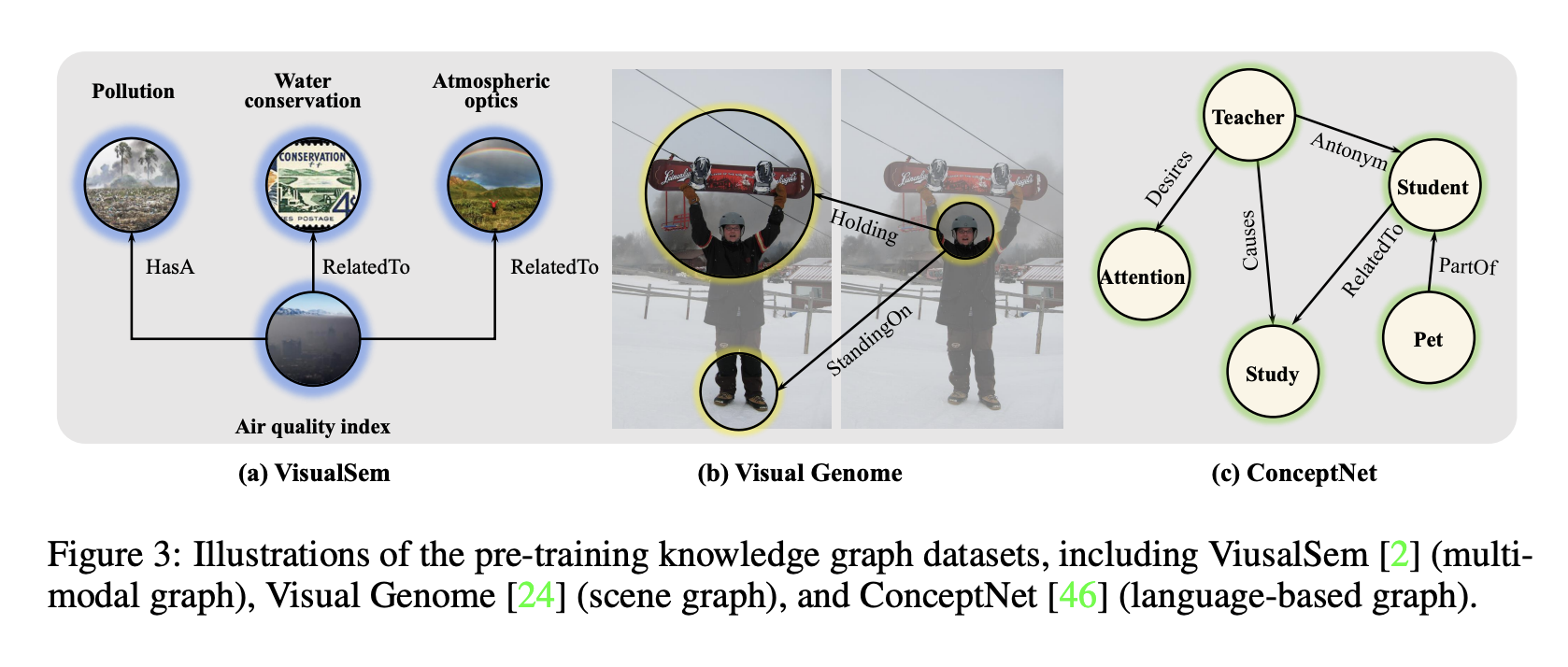
- data : VisualSem(WordNet + ImageNet), Visual Genome, ConceptNet, COCO Caption, CC3M
- result : SOTA.
- contribution : formulate data in the form of a triplet so that it can be CLIP trained.
Details
Motivation
Dataset
Additionally, for image-text pairs, you can arbitrarily specify a relation, such as is a image of, is a caption of, to make it a triplet.
Architecture
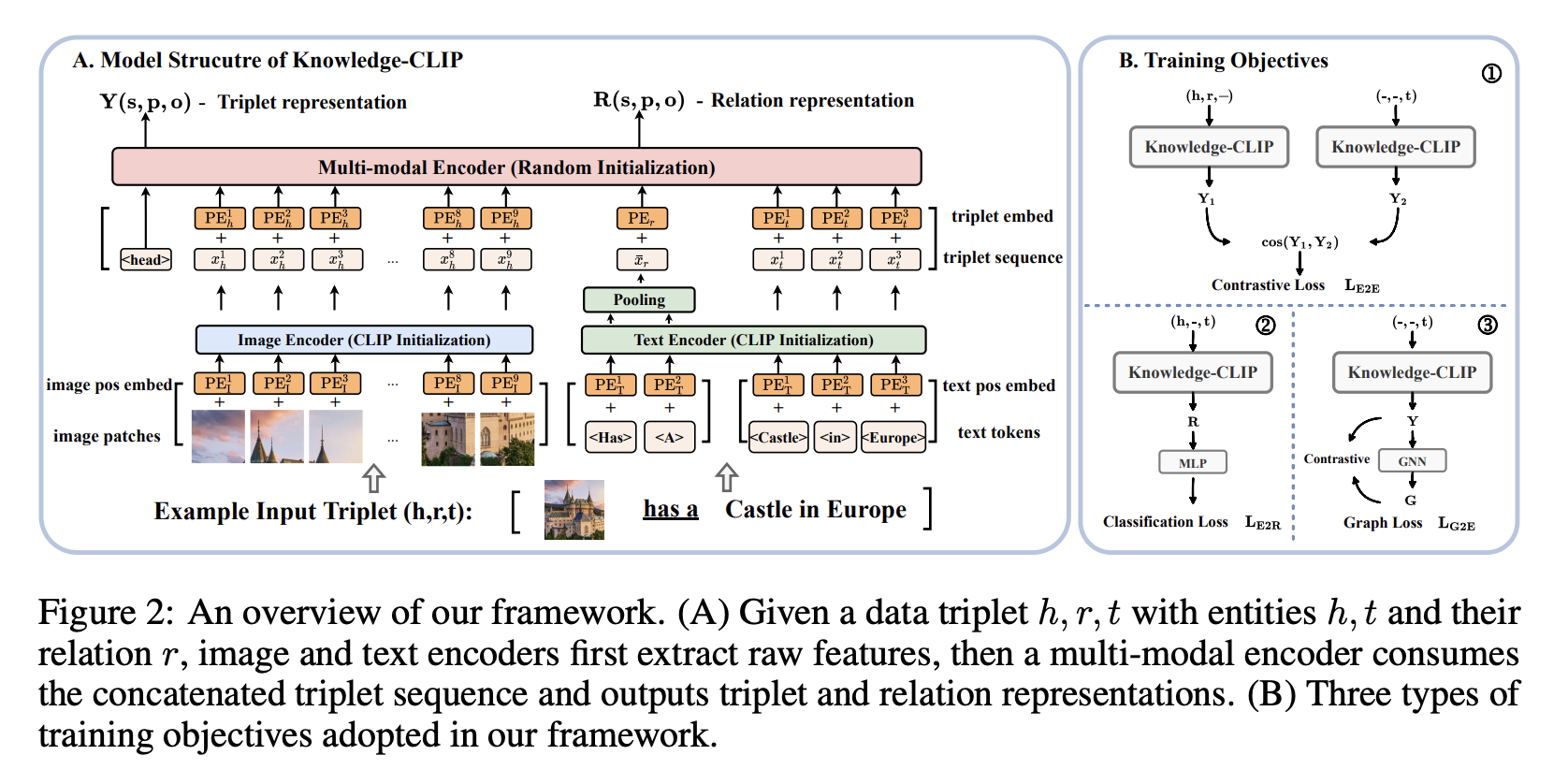
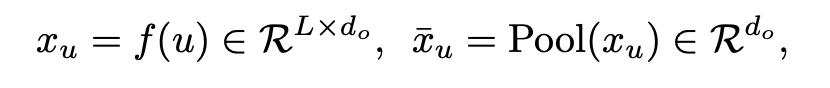
- f$ is a text or image encoder
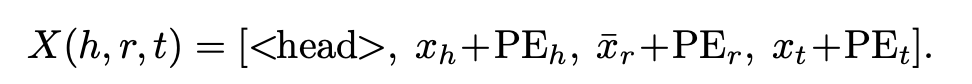
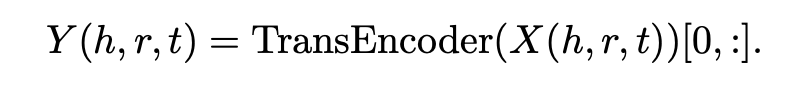
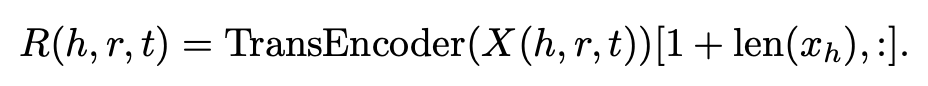
Just index the representation for the relation
Loss
- Triplet based loss Like mlm, we’re going to cover up some of the triplet elements and ask you to guess
E2E loss
If the entity (head or tail) is masked, estimate the loss as below
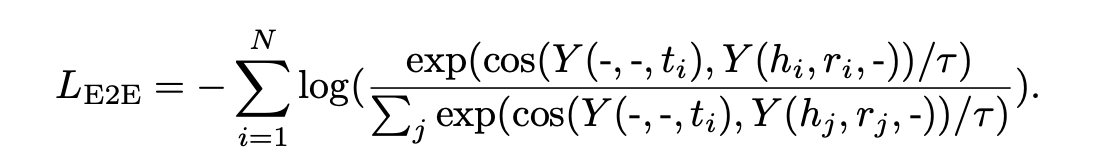
Masking is just a 0 vector cat format
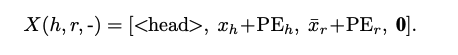
To make the representation of a tail and the representation of a head, relation that is part of the same triplet as that tail, closer together.
E2R loss
Matching relation is just a matter of categorization
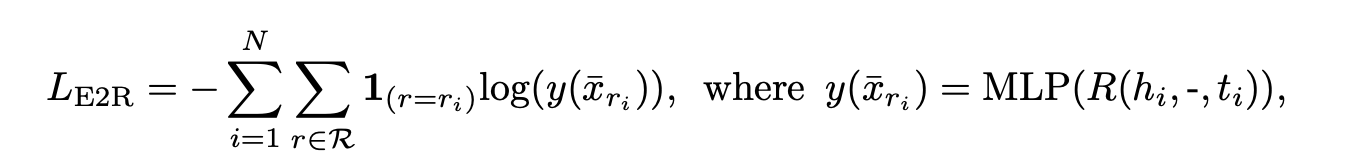
- Graph-based loss
To make the entity representation similar between the GNN and transformer passes, we’ll use the
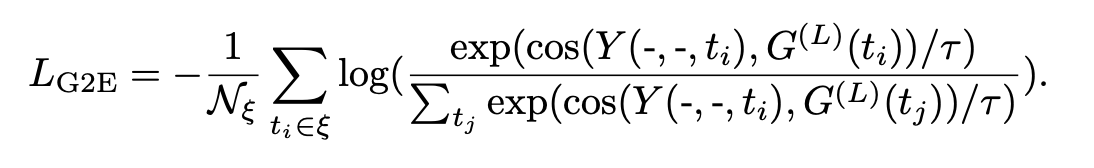
Continuous Learning
KL Divergence with Results from Pretrained CLIPs
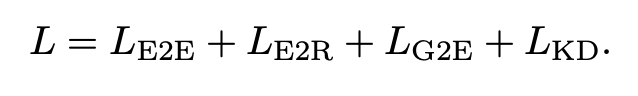
Experiement setup

Result
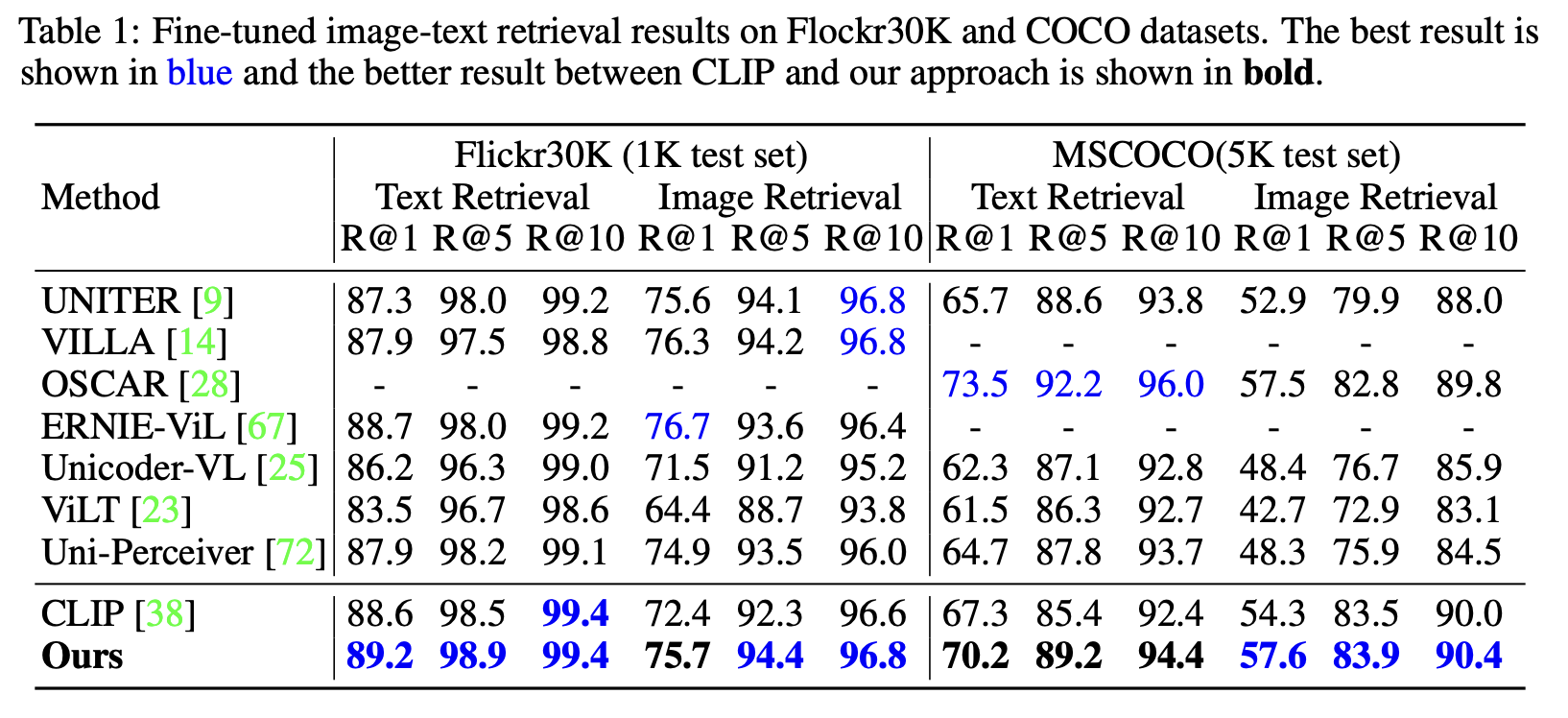
Image Retrieval
VQA, SNLI_VE
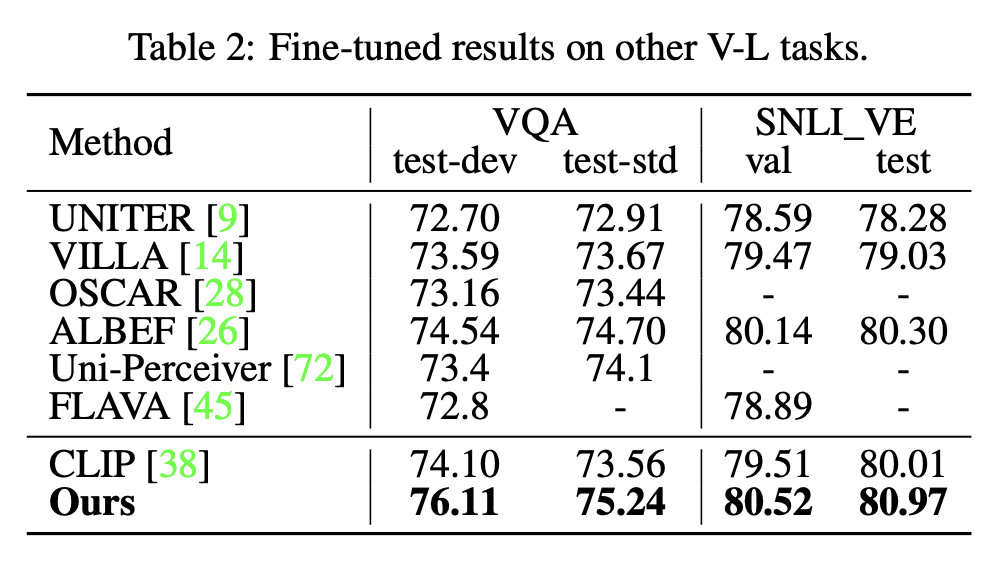
snli_ve is said to be this data.
 https://github.com/necla-ml/SNLI-VE
https://github.com/necla-ml/SNLI-VE
GLUE
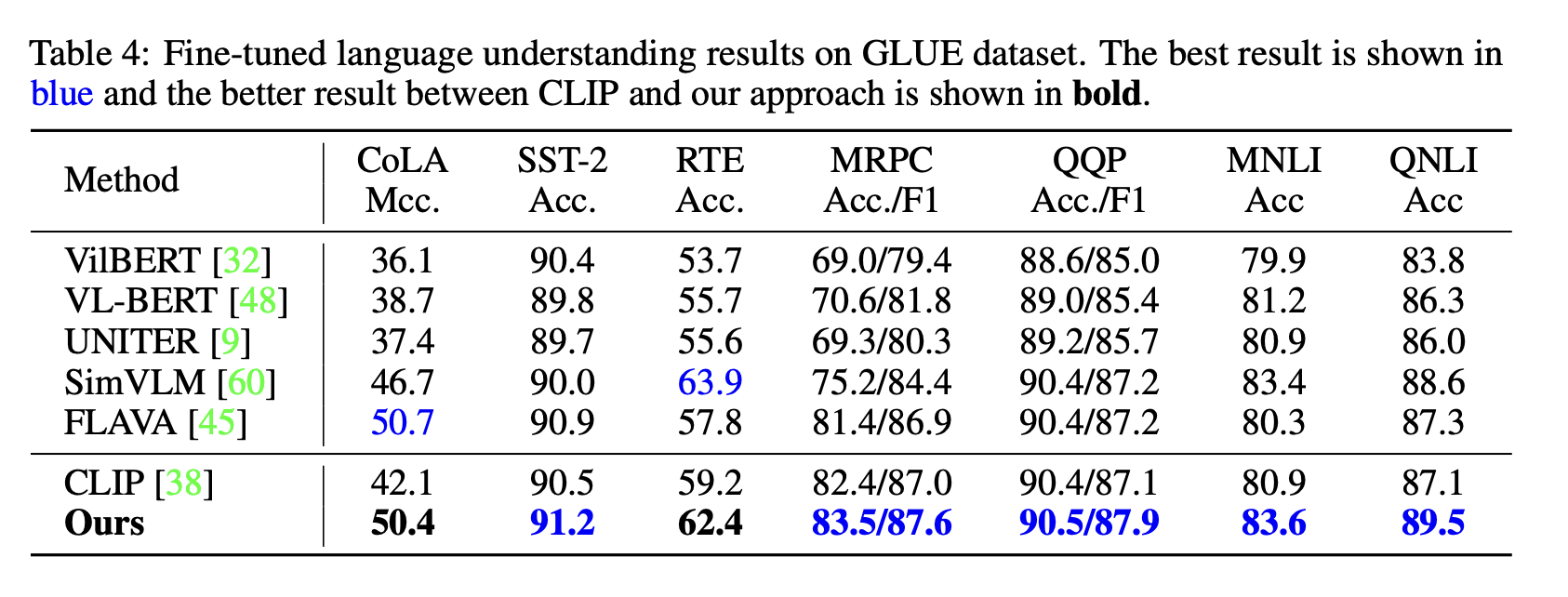
Image Classification

Ablation
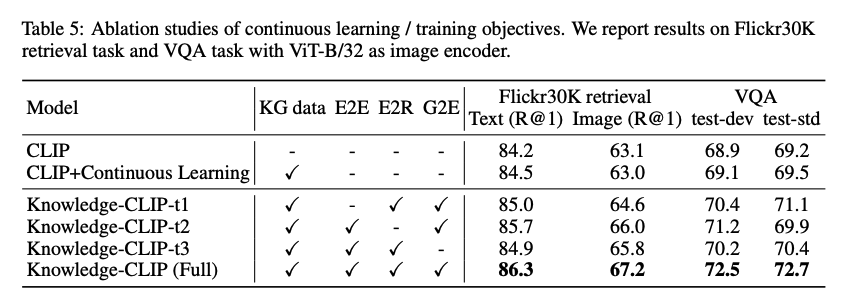
- Better than CLIP + KG
Did you solve the problem from motivation?
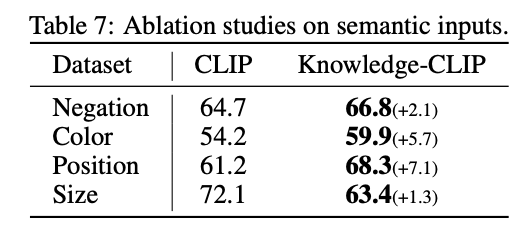
We reran the evaluation only for VQAs with properties like color in VQA, and it performed better.