TL;DR
- task : long-tail object detection
- problem : COCO data is annotated with long-tail and trained accordingly, but the evaluation metric, mAP, is AUC, so there is a gap.
- idea : Optimize this by replacing mAP probabilistically and bounding it by a weighted version of the pairwise ranking error under class-margin bounds in detection (=measuring the frequency with which negative sample x’ ranks higher than positive x).
- architecture : Mask R-CNN, Cascade Mask R-CNN
- objective : ECM loss
- baseline : CE Loss, Federated Loss, Seesaw Loss, LOCE loss
- data : LVIS v1, Open Images
- result : SOTA
- contribution : no hyper-parameter for long-tail problem
- Limitations or things I don’t understand : I don’t understand all the formulas. It says there is no penalty effect for duplicate object. Doesn’t it work with DETR?
Details
related work
Long-tail Detection related work
- Approaches that implicitly/explicitly re-weight losses, as most of the literature does.
- Equalization loss: how to remove negative gradients for rare classes
- Assumption that rare classes are discouraged by negative gradients of other classes
- Balanced Group Softmax (BaGS): divides groups by frequency in the training set and gets softmax + cross-entropy from there
- federated loss: computes only the negative gradient of the class from the image
- Equalization Loss V2: Trying to match the cumulative ratio of positive/negative by class
- SeeSaw loss: reduces weight for negative gradients in rare classes with high frequency
Learning with class-margins
- It sounds like face-recognition, and it’s used a lot.
- Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
Key Developments
- preliminary: class-margin bound
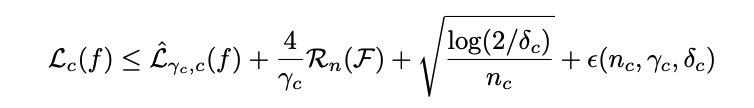
As if finding the class loss with margin means the loss is smaller than just finding the class loss? This formula is proven in another paper
- Decision Metrics : mAP
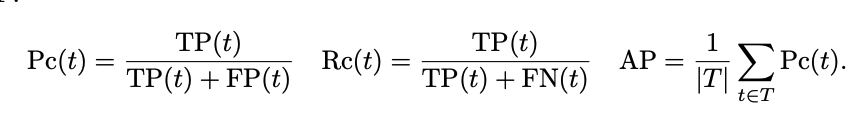
Replace this with probabilistic, which would look like this
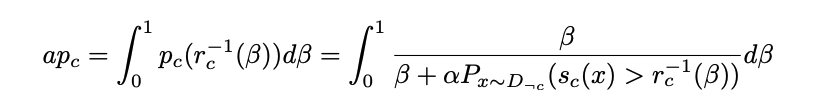
This can be bounded by a weighted pair-wise ranking error with a class margin bound
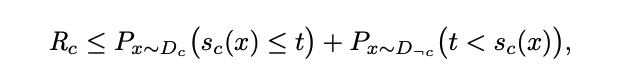
In this case, the pair-wise ranking error is the frequency with which negative sample x’ is ranked higher than positive sample x.
where the ranking loss can also be bounded by a binary error with a threshold added
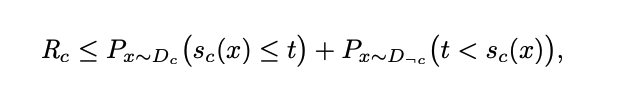
How to organize this expression… Combined with the class-margin bounds above, this gives the tightest margin
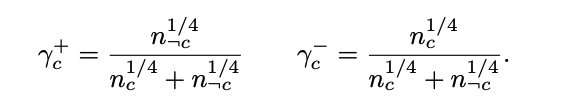
To recap, we want to minimize the margin-based error, which means applying a sigmoid whose threshold is the margin rather than 0.5, and the
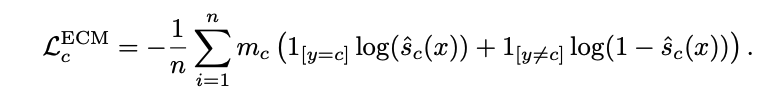
- where $m_c$ is the value for bounding the ranking error, which is also expressed as bound
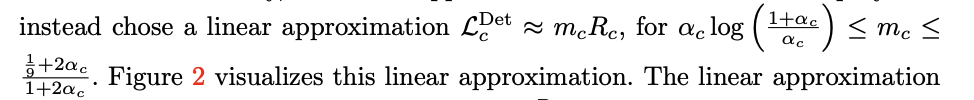
In this case, the score function is a weighted sum with the tightest margin
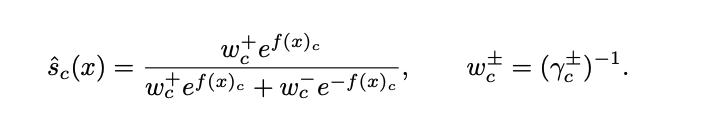
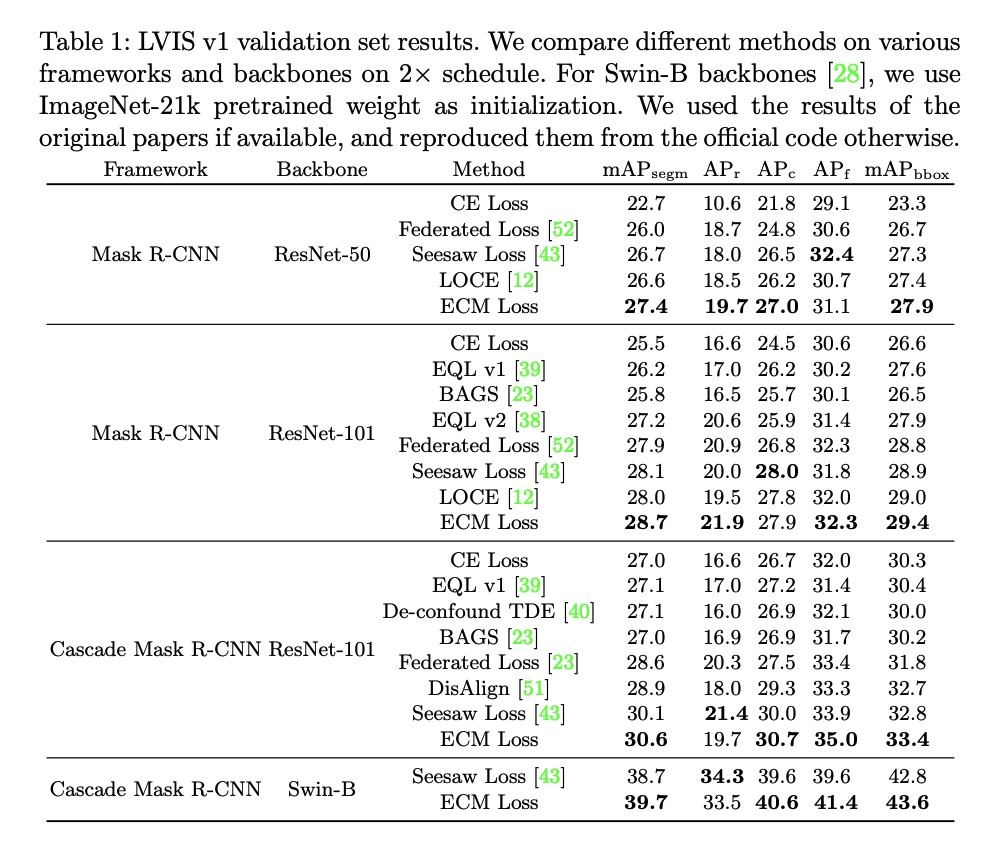
Results