
TL;DR
- task : deep saliency map
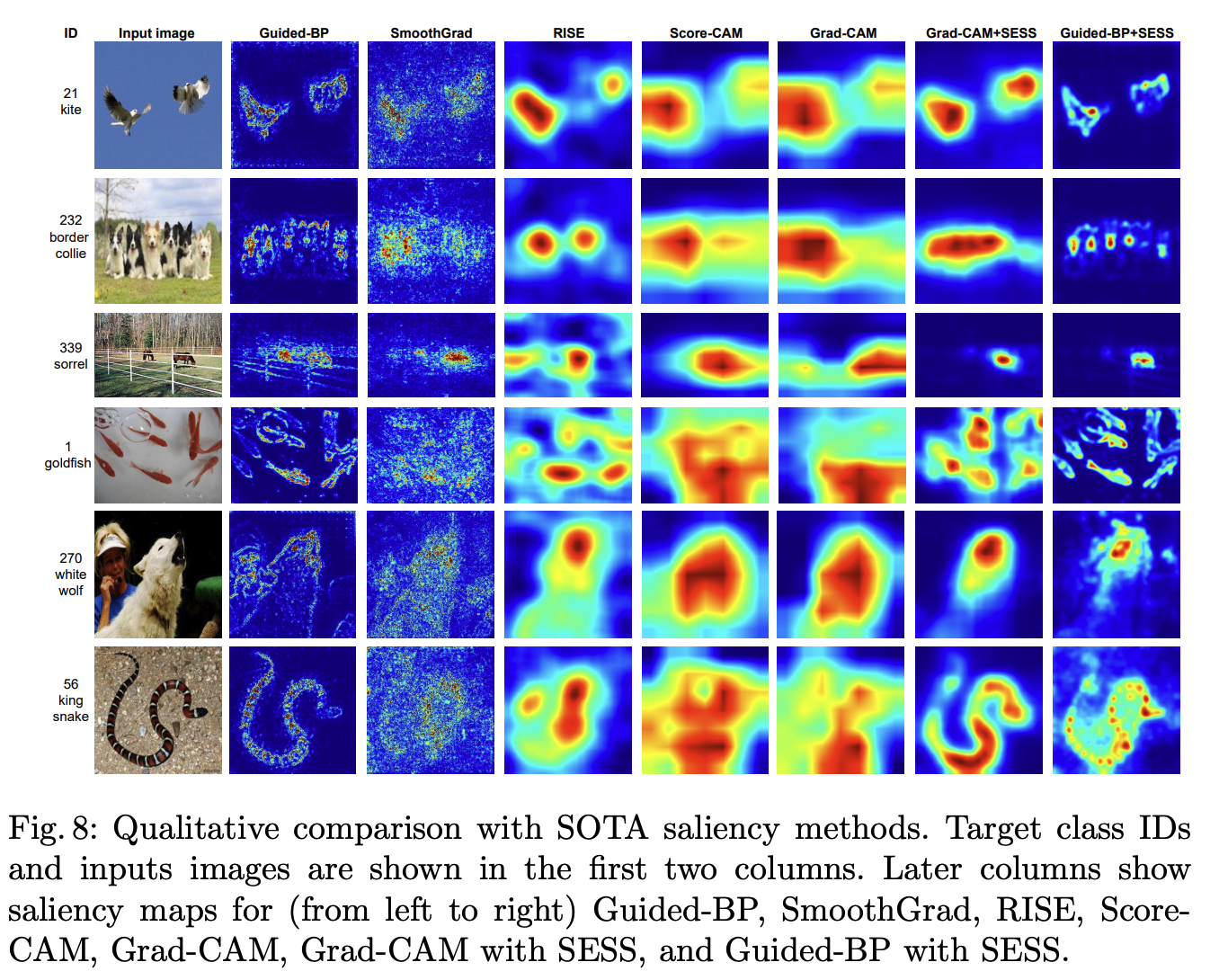
- problem : Existing methodologies have 1) weak scale invariance 2) poor detection of multiple objects 3) distactor dependent 4) noisy for gradient based visualization 5) poor distinction in case of GradCAM (e.g. snake photo below) 6) input size is often fixed, so resizing is required and the resolution and image ratio change, resulting in poor results.
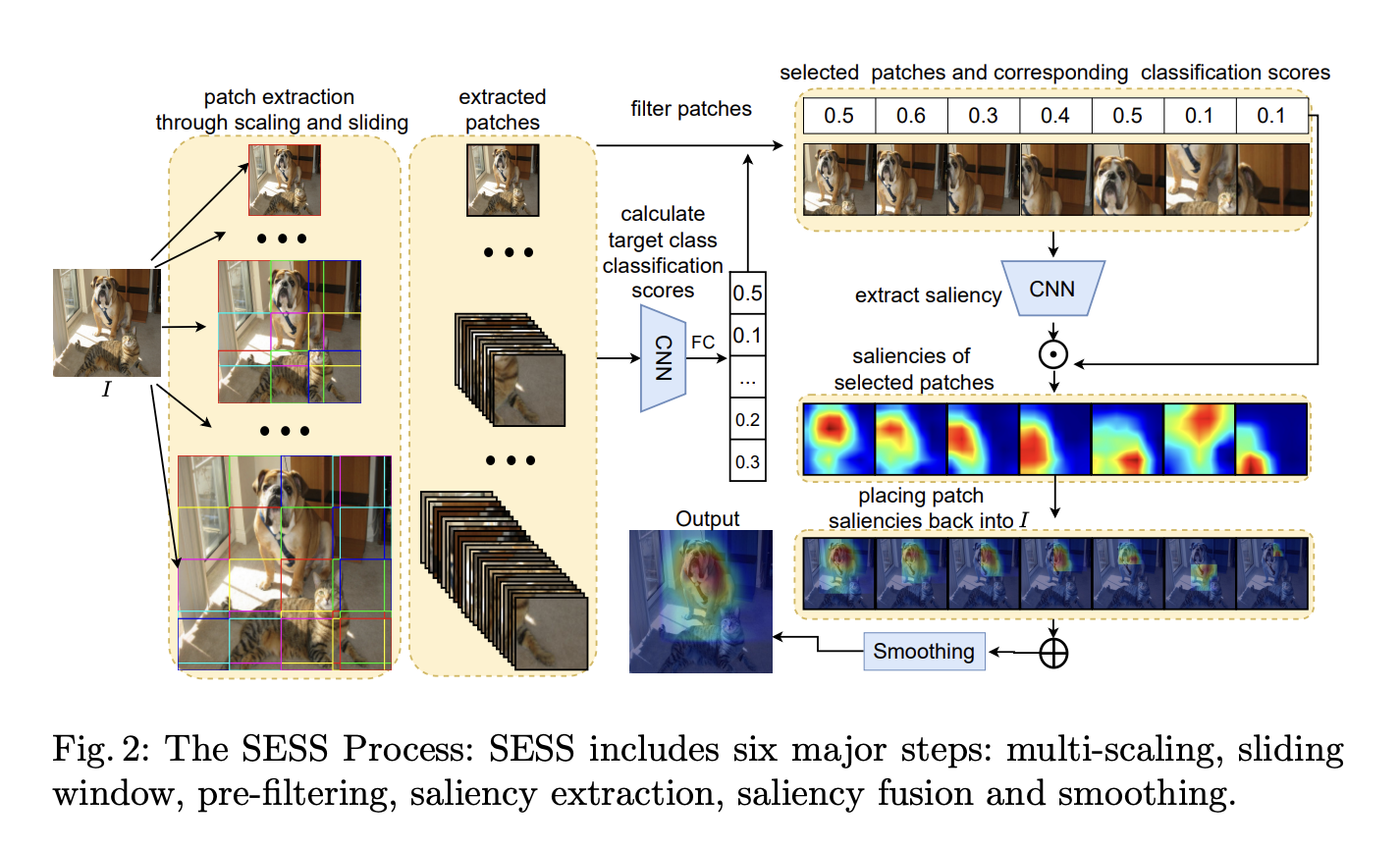
- idea : Let’s make a saliency map by dividing the image into multiple inputs with multi scale, cropping them into a sliding window, and weighting the high scoring ones for that class when classified.
- architecture: add-on methodology, so it can be applied to any saliency map extraction model, including Guided-BP, CAM, GradCAM, etc.
- baseline : vanilla deep saliency map methods, RISE, XRAI
- data : ImageNet-1K, PASCAL VOC07, MSCOCO2014
- result : Faster inference than SOTA. RISE and XRAI methodologies when used with GRAD-CAM in the setting pointing game
- contribution : methodology intuitive and easy, with fast inference speed and add-on bar
- Limitations or things I don’t understand :
Details
Methodology
Qualitative result
pointing game
https://link.springer.com/chapter/10.1007/978-3-319-46493-0_33 The goal of this section is to evaluate the discriminativeness of different top-down attention maps for localizing target objects in crowded visual scenes.
Evaluation setting. Given a pre-trained CNN classifier, we test different methods in generating a top-down attention map for a target object category present in an image. Ground truth object labels are used to cue the method. We extract the maximum point on the top-down attention map. A hit is counted if the maximum point lies on one of the annotated instances of the cued object category, otherwise a miss is counted. We measure the localization accuracy by 𝐴𝑐𝑐=#𝐻𝑖𝑡𝑠#𝐻𝑖𝑡𝑠+#𝑀𝑖𝑠𝑠𝑒𝑠 for each object category. The overall performance is measured by the mean accuracy across different categories.