
TL; DR
Problem : Large annotation cost to do supervised learning. Old SSL has a complex architecture.
solution : Augment an image to learn to classify the original and augmented image as the same image. Apply contrastive loss to extract a representation from the image, transform it non-linearly, and then maximize the log softmax of the inner product of the two pairs (=minimize crossover entropy).
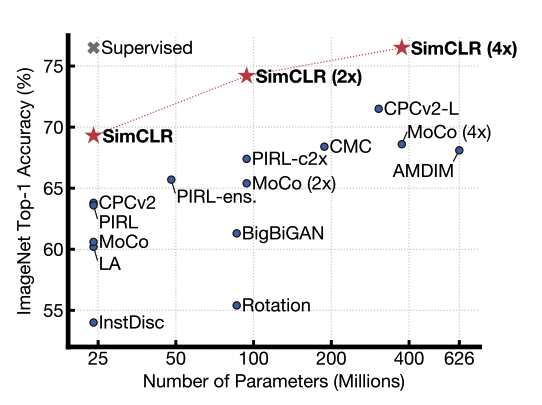
result : SOTA with top-1 accuracy 76.5% in linear evaluation on ImageNet, fine-tuned model using 1% of real data outperforms AlexNet in top-5. Also on transfer-learning, 5 out of 12 datasets outperform supervised, 5 similar, 2 worse.
Abstract
Proposed a simple framework for contrastive learning for visual representations. Learn about our three most important elements (1) The organization of data aggregation is critical to defining effective predictive tasks (2) Nonlinear transformation between representation and contrast loss is very important (3) contrastive learning requires large batch sizes and more training steps
Method
Contrastive Learning Framework

Four components
stochastic data augmentation Call x_i, x_j a positive pair if x comes from the same image with two augmentations.
base encoder f( ), which is a neural network Pull out a represntation vector for the data. ResNet + average pooling layer to make h
small neural network projection head g( ) FCN + ReLU + FCN. g( ) and find the contrast loss as z, the result of g( ). The result from f( ) above, h, shows that contrastive loss is not effective
contrastive loss function When there are k augmented samples, we need to distinguish which samples come from the same image and which do not. If you do a contrastive prediction task with N batch sizes, you will have a total of 2N data points after two types of augmentation. If we subtract the N positive pairs, we get 2(n-1) negative pairs. Find the similarity internally,

The loss function for a positive pair would look like this

Finding this for all positive pairs (i, j), (j, i) becomes the loss term, where it is divided by the temperature \tau, which we will abbreviate as NT-Xent (the normalized temperature-scaled cross entropy loss) in this paper.
Looks like softmax. Similar to triplet loss.
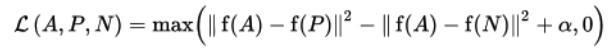
Training with Large Batch Size
Instead of using memory bank (which stores each image feature), we experimented with increasing the batch size from 256 to 8192. We used the LARS optimizer and used TPUs ranging from 32` to 128 cores, depending on the batch size, as training was unstable on larger batch sizes. Since it is designed to get positive pairs from one device, local information can be applied to the classification model. To avoid this, a global batch normalization is used to get the mean and std of all devices
Data Augmentation for Contrastive Representation Learning
More than one augmentation had to be applied to work with SSL, with the random crop + color distortion combination performing the best


Adding non-linear transformation to the representation contributes significantly to performance (3% over linear and 10% over none)
Also, using h before projection outperforms using g(z) by more than 10% -> good representation
Contributes significantly to this performance when used with contrastive loss
 . There were losses for contrastive learning. Unlike cross entropy, the other losses were not weighted by negative samples (?)
. There was a performance difference between adding L2 norm (dot product vs cosine) and tau(temperature) (L2 applied. tau=0.1)
. There were losses for contrastive learning. Unlike cross entropy, the other losses were not weighted by negative samples (?)
. There was a performance difference between adding L2 norm (dot product vs cosine) and tau(temperature) (L2 applied. tau=0.1)Larger batch size (up to BS:8192) than supervised learning, requiring longer training time