
TL;DR
- I read this because.. : NeurIPS 2023, graph
- task : multi-modal training -> image retrieval, VQA, Visual Entailment, Image Classification, GLUE
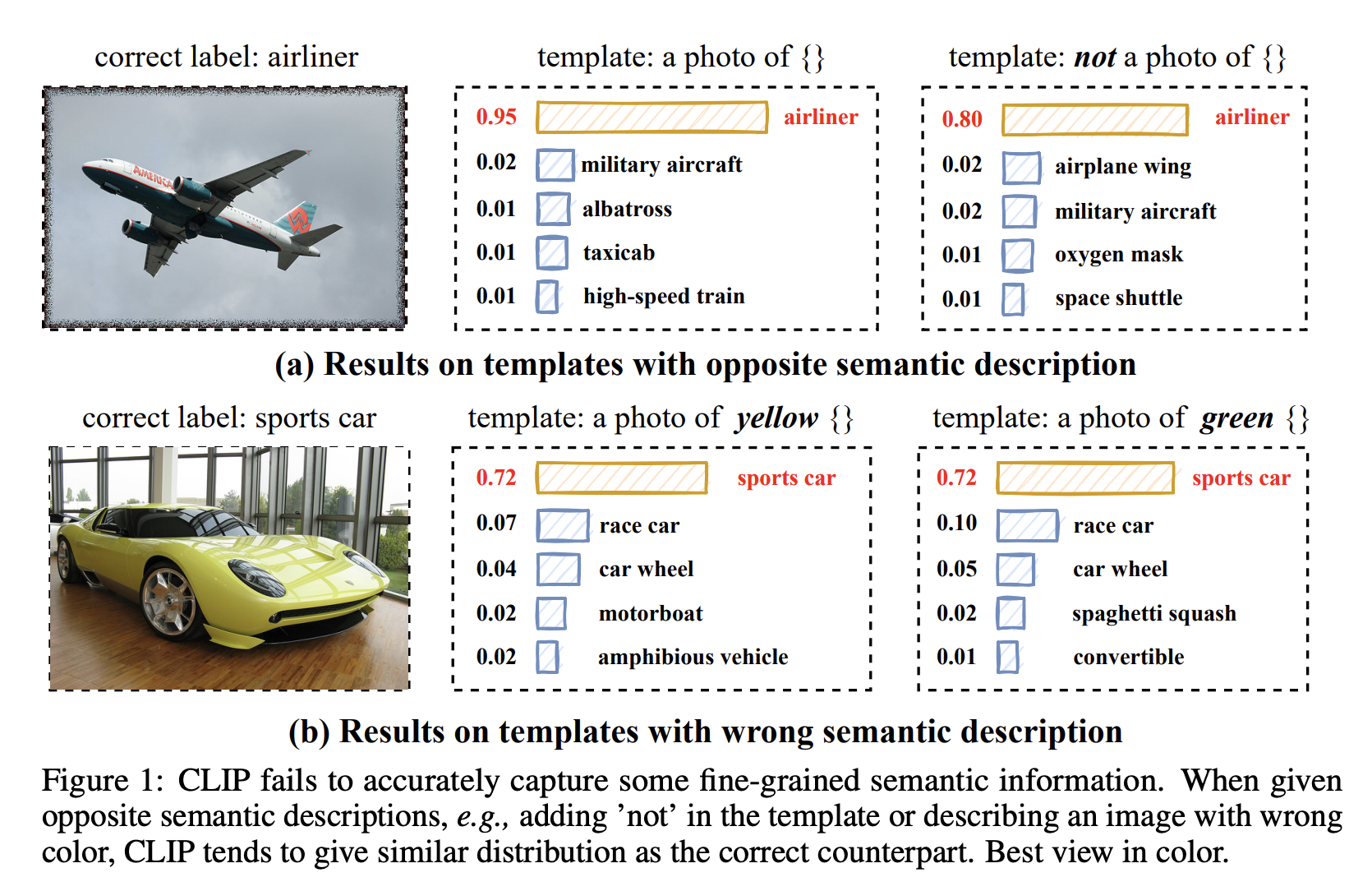
- problem : CLIP은 너무 간단하게 “match”, “not matched” 두 레이블로만 있어서 텍스트와 이미지간의 semantic한 정보를 담고 있지 않다
- idea : CLIP + knowlege graph. 인풋이 텍스트-이미지 페어가 아니라 {head, relation, tail} triplet을 받음. head나 Tail은 이미지 또는 텍스트 둘다 될 수 있음.
- architecture : CLIP 아키텍쳐를 가져가되, pooling을 하지 않고 concat + Transformer Encoder 쌓아서 Feature 뽑음
- objective : triplet에서 relation 또는 tail(또는 Head)을 지우고 예측하도록 함. 1) relation을 지울 땐 그냥 분류 문제(E2R loss) 2) tail을 지웠을 땐 tail의 표현과 head, relation의 표현이 같은 triplet을 가지고 있을 경우 가까워지도록(E2E Loss) 3) GNN 붙여서 tail에 대한 표현이 GNN 통과한 표현과 트랜스포머에 대한 표현이 비슷해지도록(E2G Loss) 4) CLIP teacher와의 KL divergence로 KD(KD Loss)
- baseline : CLIP, UNITER, OSCAR, ViLT, … 외 다수
- data : VisualSem(WordNet + ImageNet), Visual Genome, ConceptNet, COCO Caption, CC3M
- result : SOTA.
- contribution : triplet 형태의 데이터를 CLIP 학습할 수 있게 formulation.
Details
Motivation
Dataset
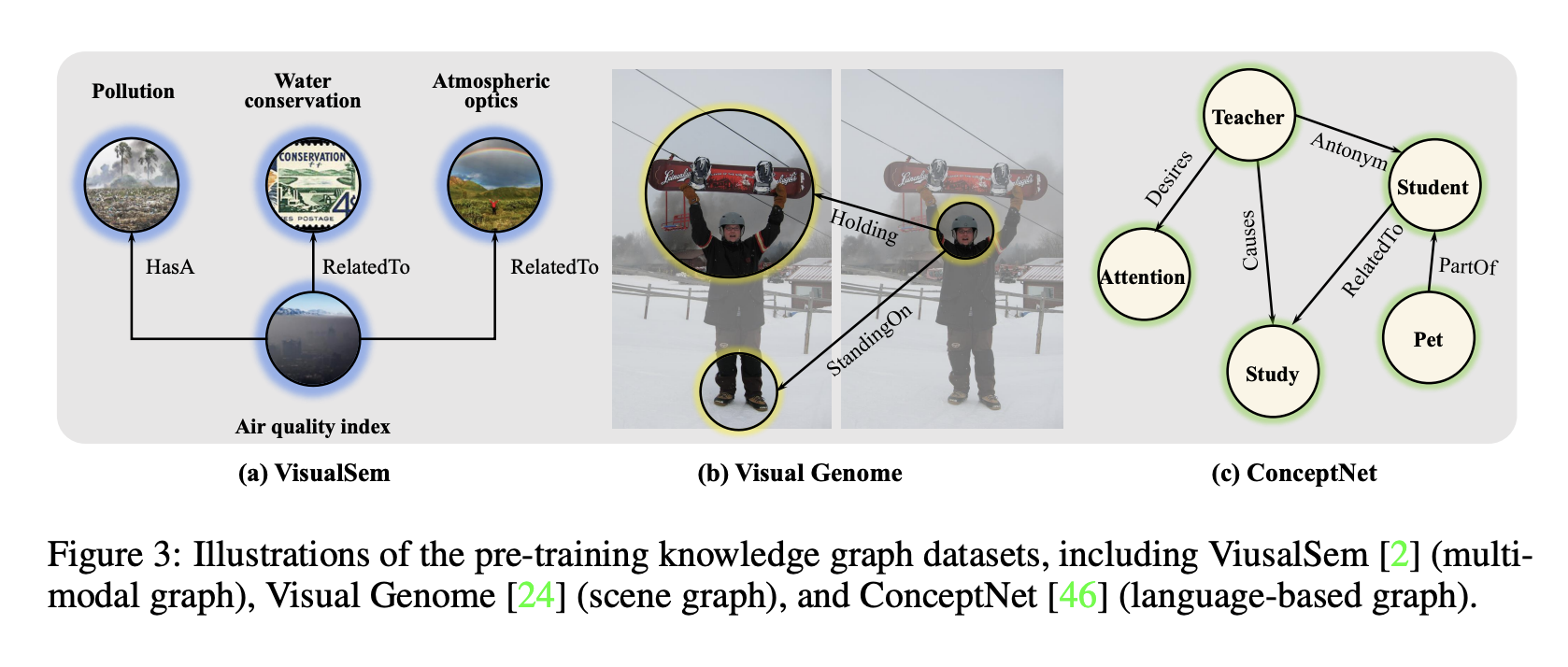
추가로 이미지-텍스트 페어의 경우 is a image of, is a caption of와 같이 relation을 임의로 지정해서 triplet으로 만듦
Architecture
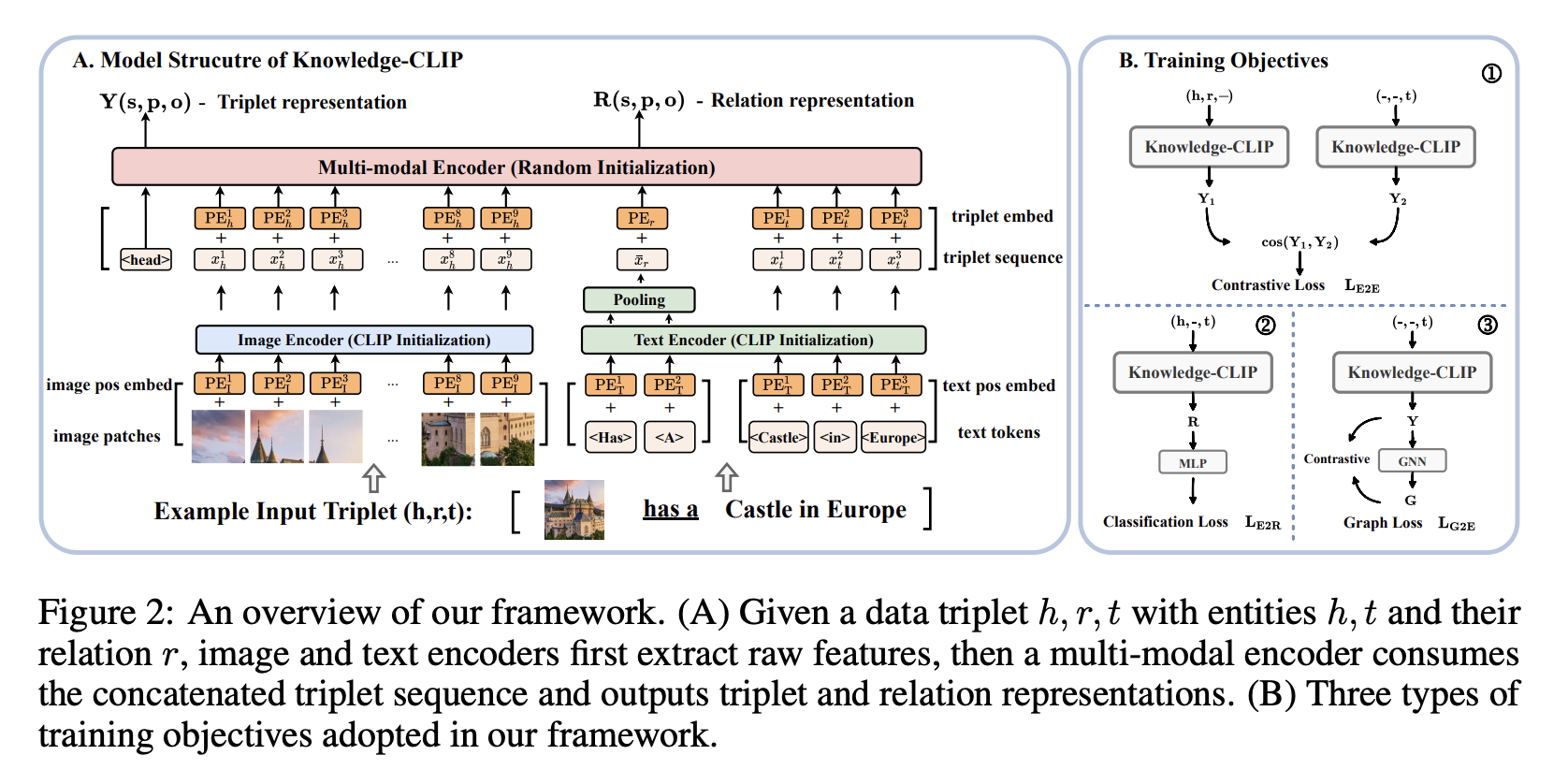
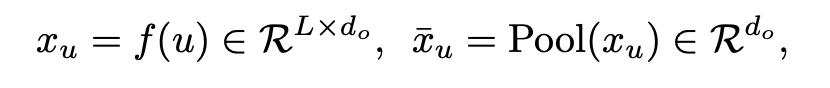
- $f$는 text 나 image encoder
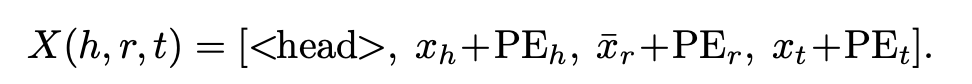
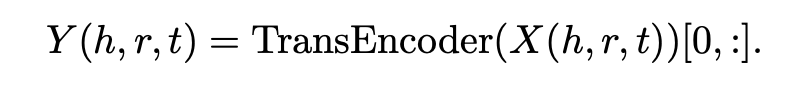
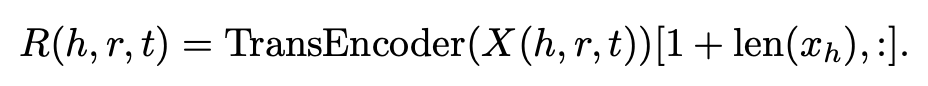
relation에 대한 표현은 그냥 인덱싱하면 됨
Loss
- Triplet based loss mlm 처럼 Triplet 요소의 일부를 가려놓고 맞추라고 할거임
E2E loss
entity (head or tail)을 가려놨을 경우 아래와 같이 loss 추정
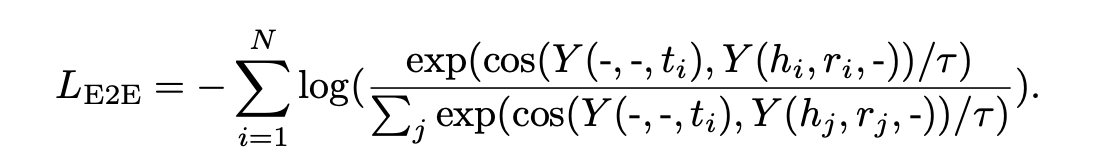
가리는건 그냥 0 벡터 cat하는 형식
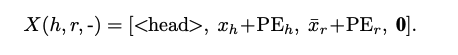
tail의 표현과 해당 tail과 같은 triplet에 속해있는 Head, relation의 표현이 가까워지도록 하는 것
E2R loss
relation 맞추는건 그냥 분류문제
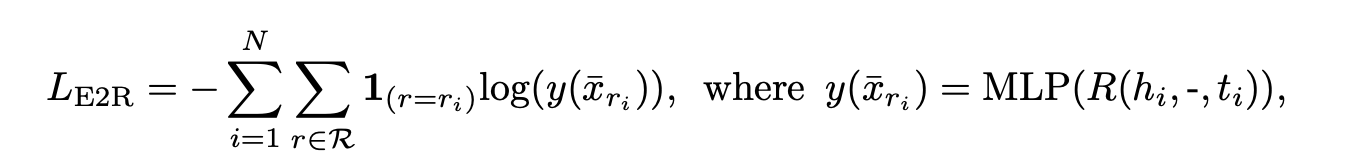
- Graph-based loss
GNN 통과시킨거랑 transformer 통과시킨거랑 entity 표현이 비슷해지도록
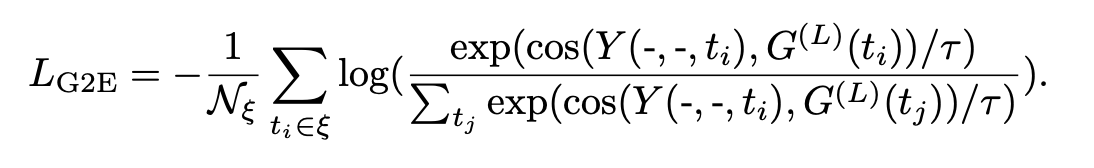
Continuous Learning
Pretrained CLIP의 결과와 KL Divergence
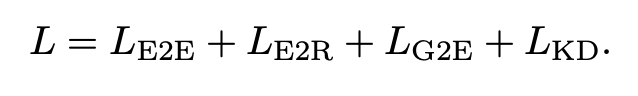
Experiement setup

Result
Image Retrieval
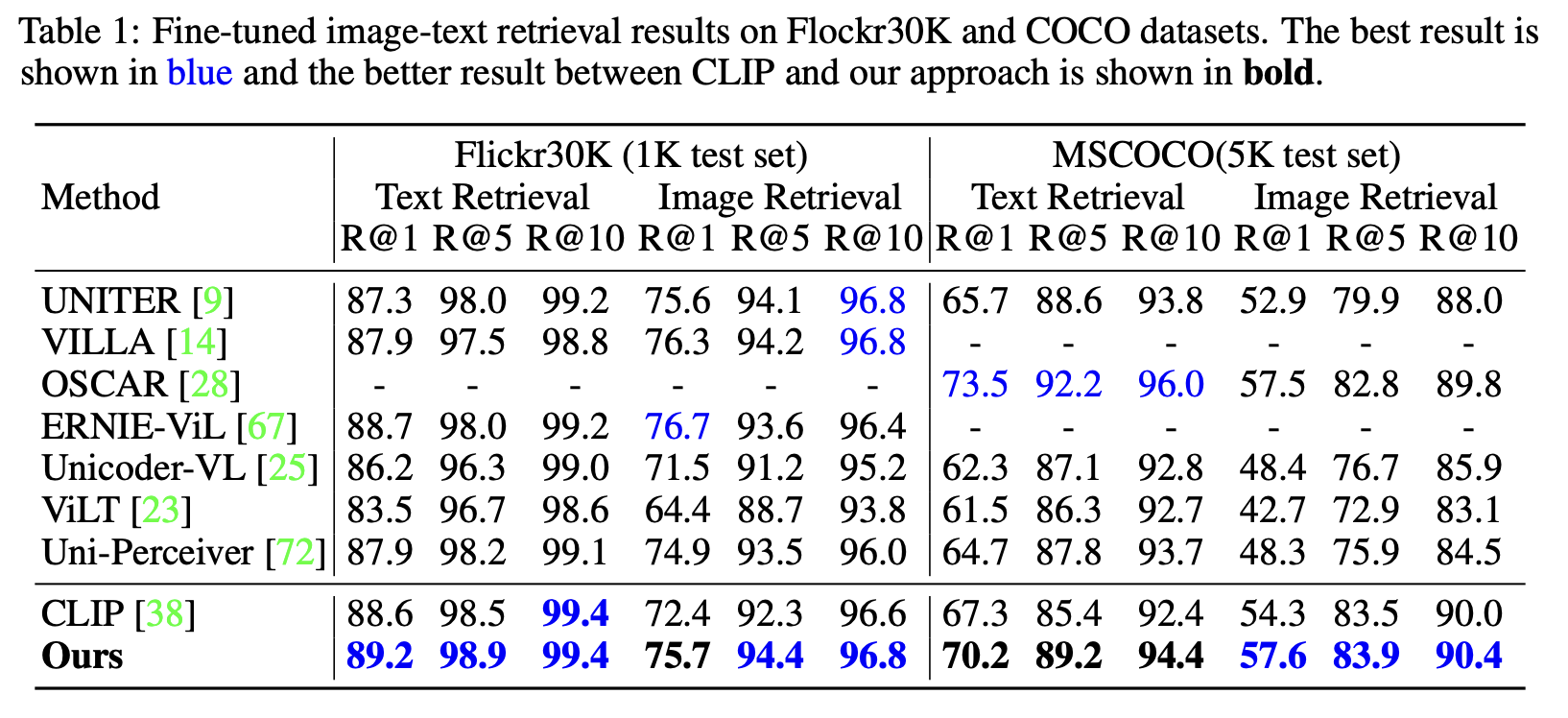
VQA, SNLI_VE
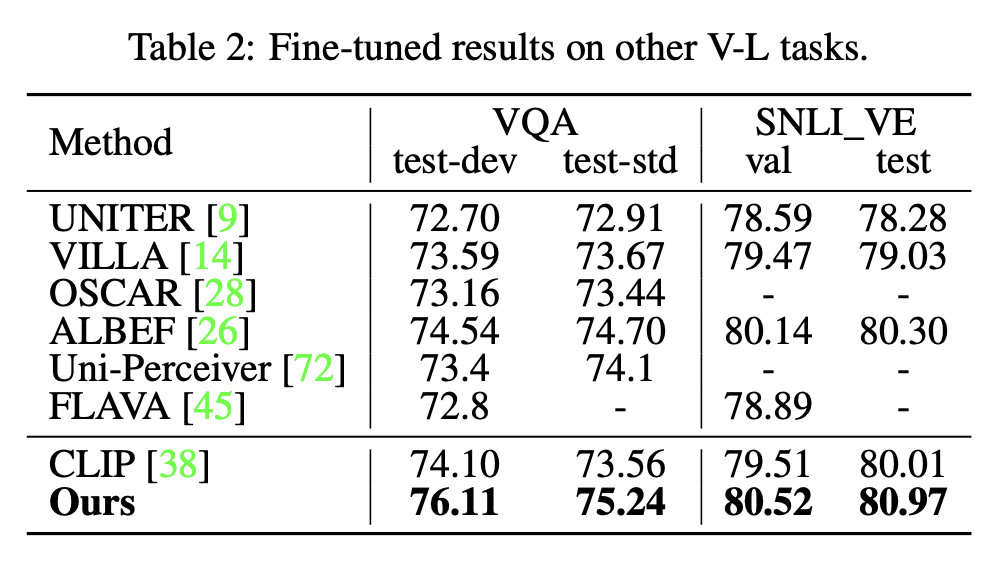
snli_ve는 이런 데이터라고 하넹
 https://github.com/necla-ml/SNLI-VE
https://github.com/necla-ml/SNLI-VE
GLUE
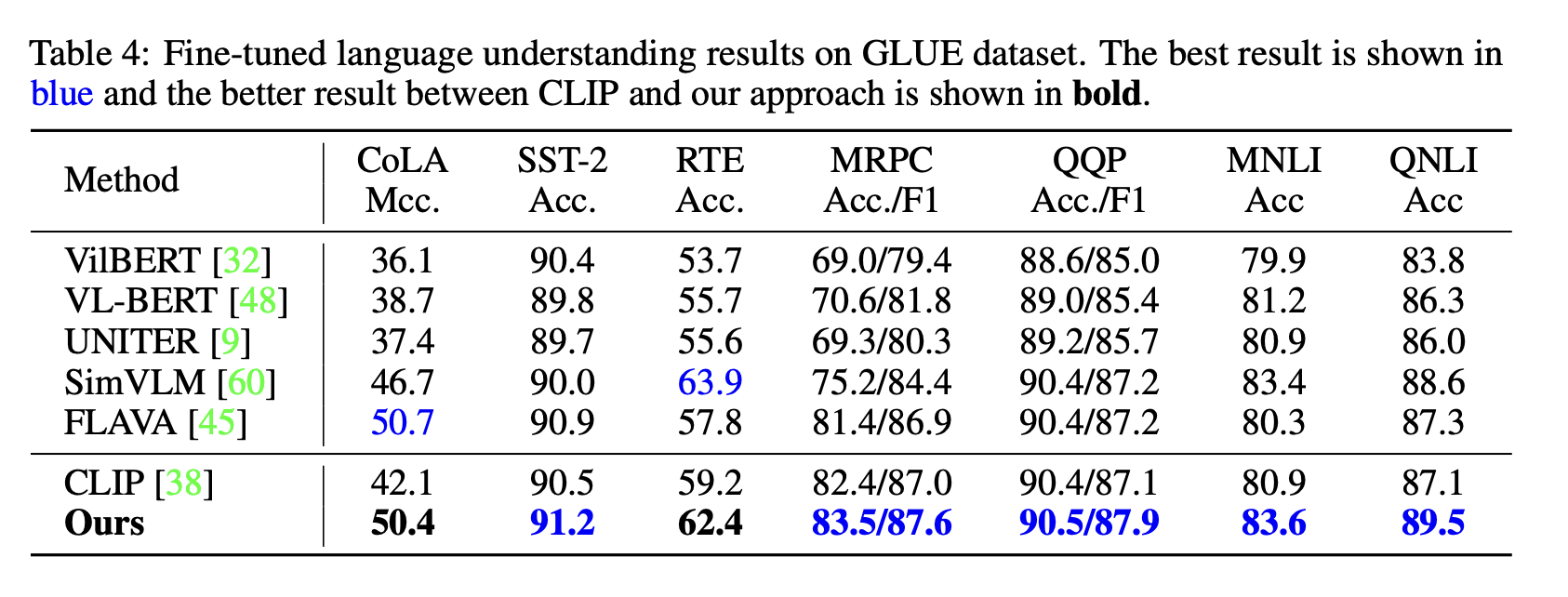
Image Classification

Ablation
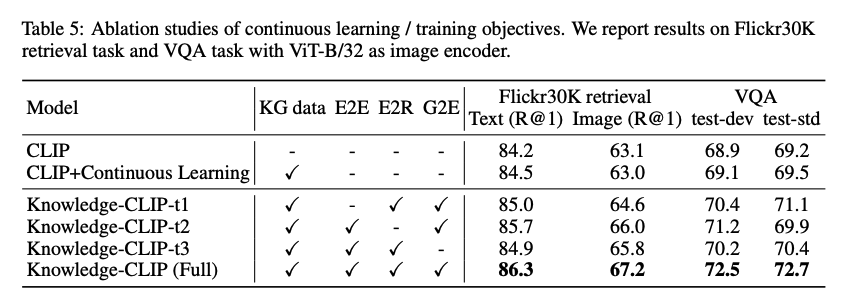
- CLIP + KG보다 성능이 좋넹
motivation에서 나온 문제를 해결했나?
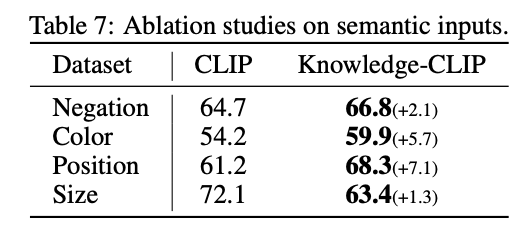
VQA에서 색깔과 같은 property를 가진 VQA에 대해서만 평가를 다시 해봤는데 성능이 더 좋았다고 한다