
TL;DR
- task : deep saliency map
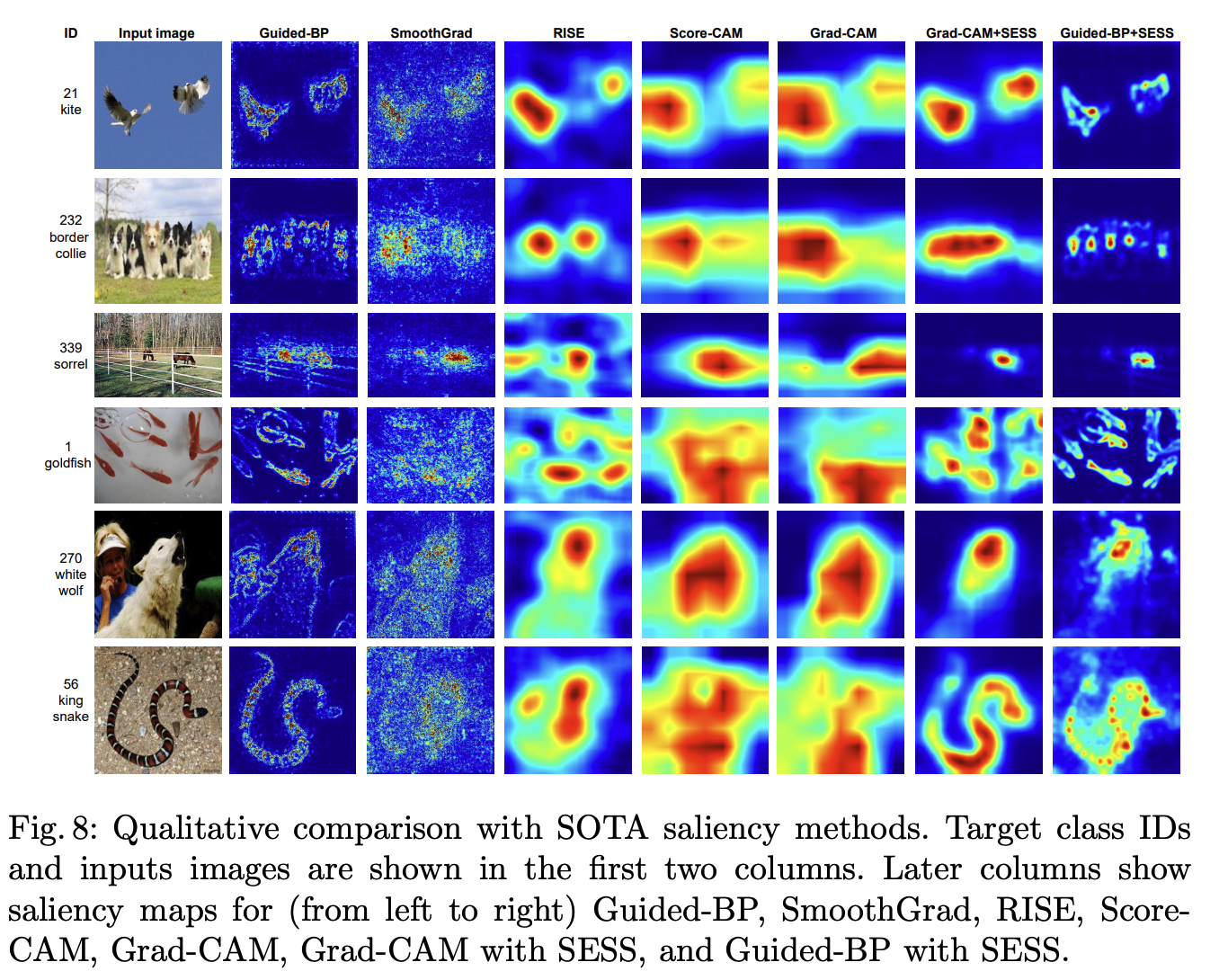
- problem : 기존 방법론들은 1) weak scale invariance 2) 여러 object 잘 못찾음 3) distactor에 영향을 받음 4) gradient based visualization의 경우 noisy함 5) GradCAM 같은 경우 구분이 잘 안됨(밑의 뱀 사진 같은 예시) 6) input size가 고정되어 있는 경우가 많아서 resize를 해야되고 해상도와 이미지 비율이 바뀌어서 결과가 안좋음
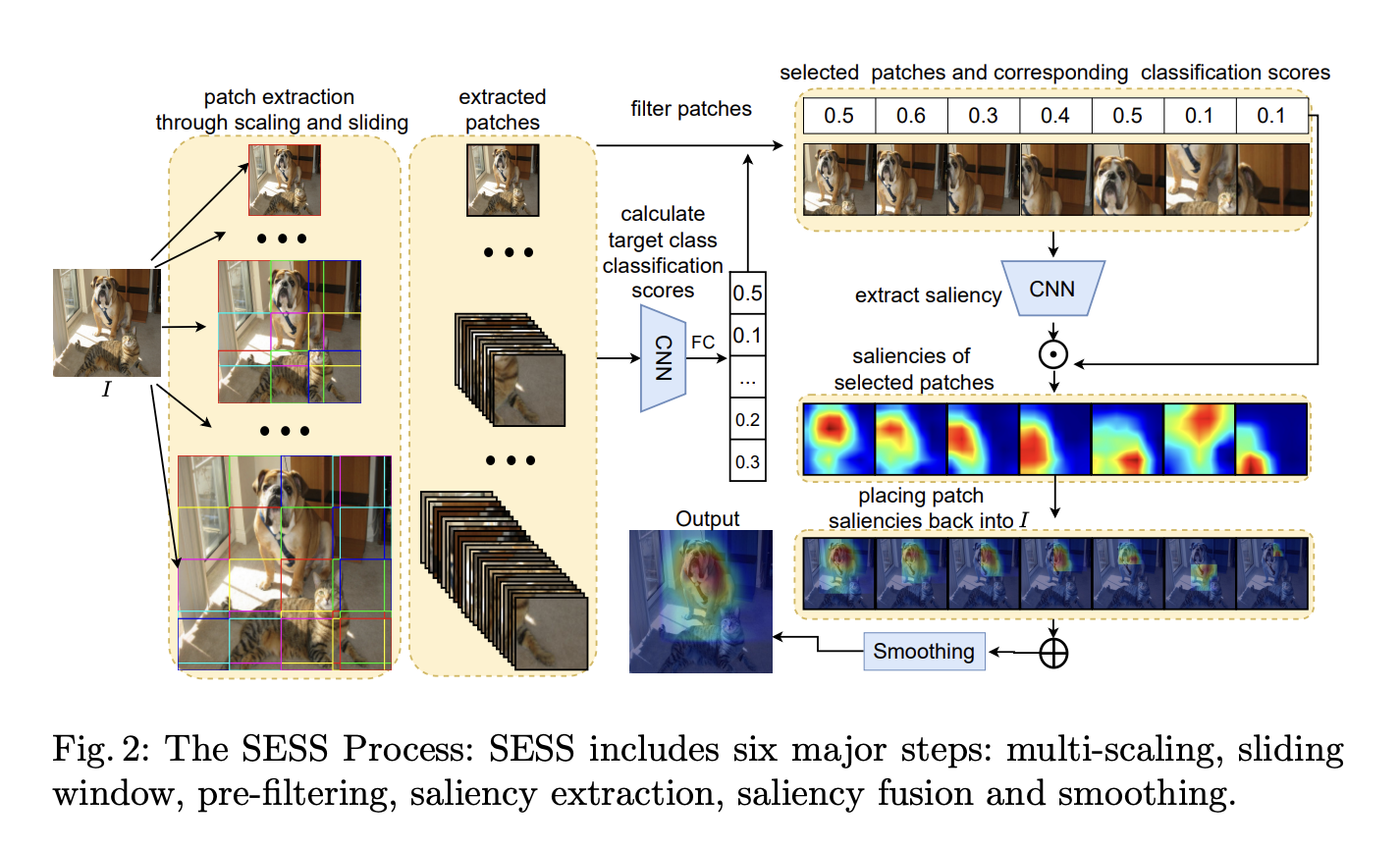
- idea : 이미지를 mult-scale로 여러 input으로 나눈 뒤에 sliding window로 자르고, classification 했을 때 해당 class에 대한 scoring이 높은 것들을 가중합해서 saliency map을 만들자
- architecture : add-on 방법론이라 Guided-BP, CAM, GradCAM 등 어느 saliency map 뽑는 모델이든 적용할 수 있음
- baseline : vanilla deep saliency map methods, RISE, XRAI
- data : ImageNet-1K, PASCAL VOC07, MSCOCO2014
- result : pointing game 이란 setting에서 GRAD-CAM과 같이 썼을 때 SOTA. RISE, XRAI 방법론보다 inference 속도가 빠름
- contribution : 방법론 직관적이고 쉬운데 inference 속도가 빠른것과 add-on 바
- limitation or 이해 안되는 부분 :
Details
Methodology
Qualitative result
pointing game
https://link.springer.com/chapter/10.1007/978-3-319-46493-0_33 The goal of this section is to evaluate the discriminativeness of different top-down attention maps for localizing target objects in crowded visual scenes.
Evaluation setting. Given a pre-trained CNN classifier, we test different methods in generating a top-down attention map for a target object category present in an image. Ground truth object labels are used to cue the method. We extract the maximum point on the top-down attention map. A hit is counted if the maximum point lies on one of the annotated instances of the cued object category, otherwise a miss is counted. We measure the localization accuracy by 𝐴𝑐𝑐=#𝐻𝑖𝑡𝑠#𝐻𝑖𝑡𝑠+#𝑀𝑖𝑠𝑠𝑒𝑠 for each object category. The overall performance is measured by the mean accuracy across different categories.