
TL; DR
problem : supervised learning을 하기 위해 큰 annotation 비용. 이전의 SSL은 복잡한 아키텍쳐를 가지고 있음.
solution : 이미지를 augmentation하여 원래 이미지와 augmented image가 같은 이미지로 분류되도록 학습. 이미지에서 representation을 하고 이를 non-linear로 transform한 뒤 두 pair의 내적 곱의 log softmax가 최대화(=크로스엔트로피 최소화)하도록 하는 contrastive loss 적용.
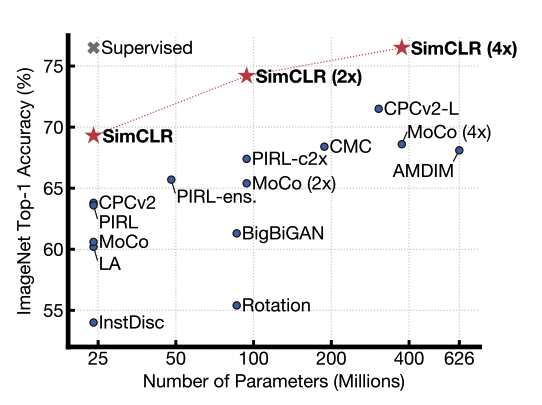
result : ImageNet에 대해 linear evaluation했을 때 top-1 accuracy 76.5%로 SOTA, 실제 데이터의 1%를 사용하여 fine-tuning한 모델이 top-5에서 AlexNet보다 더 좋은 성능. transfer-learning에서도 12개 데이터셋 중 5개는 supervised 보다 나은 성능, 5는 유사, 2는 떨어짐.
Abstract
visual representation을 위한 contrastive learning을 위한 간단한 프레임 워크를 제안. 우리의 가장 중요한 세가지 요소에 대해 학습 (1) 데이터 어그멘테이션의 구성이 효과적인 예측 태스크를 정의하는데 중요하게 작용함 (2) representation과 contrastive loss 사이의 nonlinear한 transformation이 매우 중요함 (3) contrastive learning은 큰 배치사이즈와 더 많은 트레이닝 스텝을 필요로 함
Method
Contrastive Learning Framework

4가지의 구성요소
stochastic data augmentation 같은 이미지에서 나온 x를 두개의 augmentation을 적용하여 나온 x_i, x_j를 positive pair라고 부름
neural network인 base encoder f( ) 데이터에 대해 represntation vector를 뽑아냄. ResNet + average pooling layer를 거쳐 h를 만듦
small neural network projection head g( ) FCN + ReLU + FCN. g( )의 결과물인 z로 contrastive loss를 구함. 위의 f( ) 에서 나온 결과물인 h로 contrastive loss가 나오는 것이 효과적이지 않음을 보임
contrastive loss function k개의 augmented sample이 있을 때, 같은 sample에서 나온 이미지에서 나온 sample과 그렇지 않은 sample을 구분해야함. N개의 batch size로 contrastive prediction task를 하면, 두 종류의 aug를 지나면 총 2N개의 데이터가 생긴다. 이 때 N개의 positive pair를 빼면 2(n-1) 개의 negative pair가 생긴다. 유사도를 내적으로 구하고,

positive pair에 대한 loss function은 아래와 같이 된다.

이를 모든 positive pair (i, j), (j, i)에 대해 구하는 것이 loss term이 되고, 여기서 temperature \tau로 나누어주므로 줄여서 본 논문에서 NT-Xent(the normalized temperature-scaled cross entropy loss)
softmax처럼 생김. triplet loss 랑 비슷함.
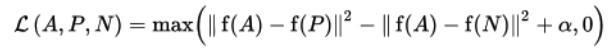
Training with Large Batch Size
memory bank (각 이미지 feature를 저장해 둠)를 사용하는 대신, batch size를 256~8192까지 늘려보어 실험해보았다. 큰 배치사이즈에서는 학습이 불안정하여 LARS optimizer 를 사용했고, 배치사이즈에 따라 32`~128 core의 TPU를 사용했다. 한 device에서 positive pair가 들어가도록 디자인되기 때문에 로컬 정보가 분류 모델에 적용될 수 있음. 이를 방지하기 위해 모든 device의 mean과 std를 구하는 global batch normalization이 사용됨
Data Augmentation for Contrastive Representation Learning
SSL에 적용하기 위해는 두개 이상의 augmentation을 적용해야 했고, random crop + color distortion 조합이 가장 성능이 좋았음


representation에 non-linear transformation을 추가하는 것이 성능에 크게 기여함(linear 보다 3%, 없는것보다 10%이상)
또한 projection을 하기 전의 h를 사용하는 것이 g(z)를 사용하는 것보다 성능이 10%이상 차이남 -> representation이 잘됐다는 의미
contrastive loss로 사용한 이 성능에 크게 기여함
 . contrastive learning을 위한 loss들이 있었음. 이때 cross entropy와 달리 다른 loss들은 negative sample에 가중을 두지 않았음(?)
. L2 norm을 추가하는지(dot product vs cosine), tau(temperature)에 대한 성능 차이가 있었음 (L2 적용. tau=0.1)
. contrastive learning을 위한 loss들이 있었음. 이때 cross entropy와 달리 다른 loss들은 negative sample에 가중을 두지 않았음(?)
. L2 norm을 추가하는지(dot product vs cosine), tau(temperature)에 대한 성능 차이가 있었음 (L2 적용. tau=0.1)supervised learning보다 더 큰 batch size(bs:8192까지), 더 긴 학습 시간이 필요했음